2020-12-27: A story about resource pool
Intro
You might think that keeping a pool of database connections is a solved problem — just use resource-pool. However, there are still quite a few things that can go wrong once you reach a certain scale:
resource-poolimplicitly assumes that creating a connection is fast. However, if you have a cluster where nodes are added and removed dynamically, creating a connection might easily take 10+ seconds — resource-pool is not prepared to handle this out of the box.resource-poolimplicitly assumes that the connections it manages will not die unless closed explicitly. Again, this is not always the case.resource-poolbounds the maximum number of resource allocations, but not the maximum simultaneous resource allocations. It can lead to the service outage if the server can't deal with the load in certain cases.
This post will discuss these problems in-depth and demonstrate the solutions, that can be used without modifying resource-pool itself.
Problem setting.
Haskell is a high-level language: the compiler can take care of many possible bugs; there are many nice testing frameworks; the language allows separating effects from the business logic. Nevertheless, once you start interacting with the external world, there are too many things that can go wrong, and if they can go wrong, they will, once you will be on a larger scale.
In this post, I'd like to share a story about improving database connection maintenance. Basically supporting a connection pool. It may seem that this is a closed story for the Haskell ecosystem you can take a resource-pool and be happy with that. Usually, it happens to be a case, despite the few minor issues, that are out of the post's scope, resource-pool is a very stable time-proved package. But as the time showed everything is not so simple as it seems.
The basic startup code looks as:
import qualified Data.Pool
main :: IO ()
main = do
capabilities_count
<- getNumCapabilities -- (1)
pool
<- createPool
allocate
destroy
capabilities_count -- (1)
30 -- (2)
max_resources
withResource pool $ \p -> do -- (3)
...The interesting parts here are:
- (1) The package creates several 'stripes', independent resource blocks, and each capability (real OS thread that executes the Haskell code) need to take a lock on the stripe only, so if there are the same amount of capabilities as the stripes each done does not wait on a lock when dealing with resources. But the total maximum amount of allocated resources is
stripes * max_resource_per_stripe, so if the amount of threads is too high, you'll need to find the best matching stripes count. - (2) Resource lifetime, if a resource is not used more than that time, then it's freed. This approach allows giving unused resources back to the system
- (3) bracket like resource usage, in once code exits
withResourceblock resource is put back to the pool. Or if there was an exception resource is treated as dead and is freed.
The API looks quite sane and simple so far. But are there any problems? The possible problems may occur in case of implicit assumptions about the system that API or the library is based on, but that does not hold in the real system. For example, there may be an exception in the withResource scope; however, not all of them invalidate allocated resource. Still, we will always free it. It was never a problem in my practice, but it triggers a question if there is anything else not so obvious at the moment. So my path with that package was not narrow, as I'll discuss that a bit.
Problem landscape
We have one quite loaded project that requires high availability and stability. To provide such functionality, it's split into several services that differ in the resources they consume and the services they use. One of the services uses PostgreSQL as a backend; it is moderately loaded. In most cases, it has low traffic; sometimes, it gets up to 200-300 RPS. So keeping a connection pool is a viable option. The pool itself should be optimized for a case where connection grows is almost instant.
So I was using resource-pool for keeping connections to the PostgreSQL server. Really not the PostgreSQL itself but to the connection pooler odyssey (a very nice piece of software) it works like a pgbouncer but much better. One may ask why I need the cluster-wide balancer when I already have one in the program? The answer is pretty simple; if you have an only program-wide pool, then you can't scale your program easily because the maximum amount of the allocated resources may easily become higher than the database limits. So unless you have a cluster-wide pooler, you can scale your apps, you need to change its configuration. Besides, it allows hot updates of the DB, and pooler will take care of that.
The settings were set for a reasonable value, so all services combined were slightly less than the bouncer limits, each Haskell service used 2 stripes, with 4 real cores and +RTS -N4. Together that gave the best results during the stress test (with saturation around 1k RPS, 3 times more than the current maximum).
The functions itself are simple; it's just a resource allocation, see first snippet and a transaction wrapper (simplest version w/o ReadWrite/ReadOnly configuration, isolation level, and explicit commit/rollback):
transaction
:: Handle -- ^ Database handle
-> LoggerEnv -- ^ Logger handle
-> (TransactionHandle -> IO a) -- ^ User's action
-> IO a
transaction Handle {..} ctx' f = withResource dbPool $ \res ->
mask $ \release -> HS.run (HS.sql "BEGIN") res >>= \case
Left e -> case e of
HS.QueryError "BEGIN" _ _ -> throwM BeginError
_ -> throwM $ ErrorQuery e
Right{} -> do
r <- release (f (TransactionHandle res ctx))
`onException` void (HS.run (HS.sql "ROLLBACK") res)
HS.run (HS.sql "COMMIT") res >>= \case
Left e -> throwM $ ErrorQuery e
Right{} -> pure $ Right rThis code allocates a resource and runs the transaction there. In the case of exception, the transaction is rolled back, and resource is deallocated as well.
Problem 1: long connection times
The first thing that we faced with was that when we allocate a resource, it's implicitly assumed that it's quite a fast operation. I.e. you would not expect that connection to the database can take too much time, but it happens in certain situations. When resources in the cluster are reallocated, or there is temporary internal DNS problems connection could easily take up to dozen of seconds. In many cases, additional delay in a few seconds is not distinguishable from the failure. So instead of waiting 20+ seconds, you'd rather retry and use an existing connection that is allocated on 50ms at most. In such a case, you can safely (really not, but more on that later) assume that if a resource took a too long time to allocate than treat that as an allocation failure. But how could you do that? And how would you check that it's really a problem, or better even the problem?
To check that it's a problem, it's nice to add metrics around such operations. We did not do that immediately as it's required changes in the prometheus package. And changes were exposed as a prometheus-extra package (not yet in hackage). The problem is that average times (or even summary) in prometheus is not very useful as it doesn't show the full situation, and buckets histograms should be configured beforehand. To fix that WindowGauge was introduced. It reports maximum values in the window (explained in more details in my blog).
metric_open_connections :: WinGauge
metric_open_connections = unsafeRegister $
Window.gauge $ Info "ghc_db_connection_max_opened" "Maximum number of open connections in a window"
metric_in_flight :: WinGauge
metric_in_flight = unsafeRegister $
Window.gauge $ Info "ghc_db_connection_max_opening" "Maximum number of opening connections in a window"
metric_max_connection_open_time :: WinGauge
metric_max_connection_open_time = unsafeRegister $
Window.gauge $ Info "ghc_db_connection_max_open_time" "Max connect time in a window"Then you can use these metrics in the allocation and deallocation code:
new Config {..} = do
dbPool <- createPool
acquire'
(\x -> do
HC.release x
Window.decGauge metric_open_connections)
configStripes
(realToFrac configIdleTime)
configResourcePerStripe
pure Handle {..}
where
cfg = ...
acquire' = do
Window.incGauge metric_in_flight
time_started <- getTimeCoarse
go time_started
where
loop tm = HC.acquire cfg >>= \case
Right x -> do
Window.decGauge metric_in_flight
Window.incGauge metric_open_connections
now <- getTimeCoarse
let duration = now `diffTimeSpec` tm
Window.setGauge metric_max_connection_open_time (fromIntegral $ toMilliseconds duration)
pure x
Left e -> do
Window.decGauge metric_in_flight
error (show e)In acquire, we register connection as connection_in_flight, once it failed or succeeded, we unregister a connection and store time. This way, we see two metrics the maximum connection time and how many connections were simultaneous. So you can get nice plots.
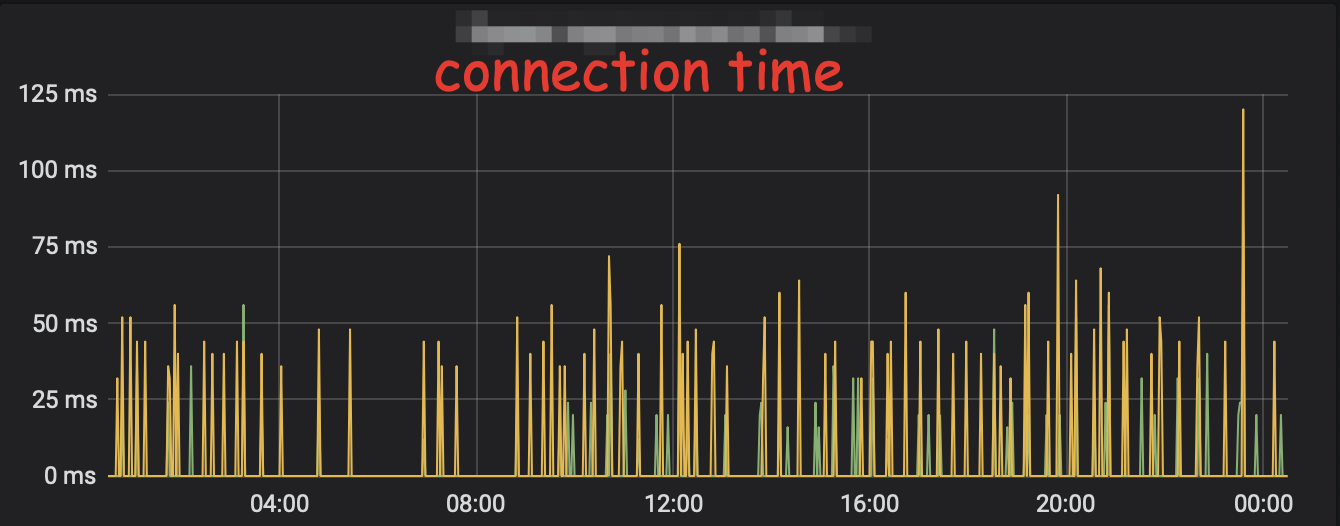
On this image everything is nice, but there were spikes. Those metrics were not ready when the first problem happened, but they were handy in many situations later. Starting from providing information to the cloud support and early problem detection and problem investigation. So the problem was there, but how to fix it?
In the base package there exists a timeout function, that is quite effective for its needs. One thing is that you should be careful enough to check that if the function is terminated on our end then so it's terminated on the other. Otherwise, you may end up with many resources still allocated on the other side. And if you do that with the connect function of the external driver and the timeout function, it's likely not a case. So the resource driver should support cancellation or timeout itself. The libpq driver supports it by additional parameter to the connection string: connection_timeout.
At this moment, the only change was in the configuration in the service.
Problem 2: dead resources
The second problem that always exists with resource-pool is that it's implicitly assumed that the resource will not die during the allowed period. So if we take a resource from the pool and try to use it, everything will be fine. Unfortunately, it's not always a case when we talk about "remote resources". One solution to such problems is a keep-alive protocol, and it's better if it's implemented in the driver, fortunately, libpg safes our day again. Adding keepalives_idle=n makes libpq driver emits idle messages on the unused connections. Again we only changed the configuration.
However, keepalives do not help in all situations. The server may still break the connection, for example during restart. The worse is that in certain situations odyssey left connections half-closed. I.e. you could take a connection from the pull start a request, and it will hang forever inside libpq call. It's not very fun to debug that with GDB :). And the only way to reproduce that in "laboratory" was to connect with gdb can call close on the connection handle. So the problem is the following, once you get a resource from the pool it may no longer be active, in this case, you don't want to throw an error but rather remove the resource from the pool and retry.
So the transaction code had to be changed:
transaction Handle {..} ctx' f = tryTransaction (0 :: Int) go
where
go =
withResource dbPool
$ \res ->
mask $ \release -> HS.run (HS.sql "BEGIN") res >>= \case
Left e -> case e of
HS.QueryError "BEGIN" _ _ -> throwM BeginError
_ -> throwM $ ErrorQuery e
Right{} -> do
r <- release (f (TransactionHandle res ctx))
`onException` void (HS.run (HS.sql "ROLLBACK") res)
HS.run (HS.sql "COMMIT") res >>= \case
Left e -> throwM $ ErrorQuery e
Right{} -> pure $ Right r
ctx = addNamespace "txn" ctx'-- | After connecton was established be employing withResource,
-- next step of opening transaction may finish with failure ("begin" query) .
-- We want on this step to recreate connection again
-- which will finish with success or throw an exception after passed number of attempts
tryTransaction :: Int -> IO (Either HS.QueryError a) -> IO a
tryTransaction cnt = go cnt
where
go i trans
| i == 10 = throwM $ ConnectionLost i
| otherwise =
E.try trans >>=
\case Left BeginError -> go (i + 1) trans
Right (Left e) -> throwM $ ErrorQuery e
Right (Right x) -> pure xThis change solved the problem of hanging connections and stress tests in the cloud (managed solution) and in the hosted environment showed that everything worked in case of the restarts.
Problem 3: cascading failures.
Another implicit assumption is that connection allocations are independent of each other. Resource pool package allows n concurrent allocations where n=stripes*resource_per_stripe.
It may be a very high number. But it's not always a case if you have SSL connections creation of either one takes up to 200ms (by words of the cloud support), but if there are too many connections, it could take too much CPU, increasing connection a time a lot. For example, up to 30s or a minute. But remember on step 1 we set up connection_timeout. It happened that even libpq dropped the connection after timeout, odyssey and Postgres did not. So the server actually processed a connection even if it would be terminated. On the other side, the package tries to connect again and again. That lead to the service DDoS itself.
Remember the metrics that were introduced; they helped here verify a strong correlation between the number of messages in-flight and max connection time.
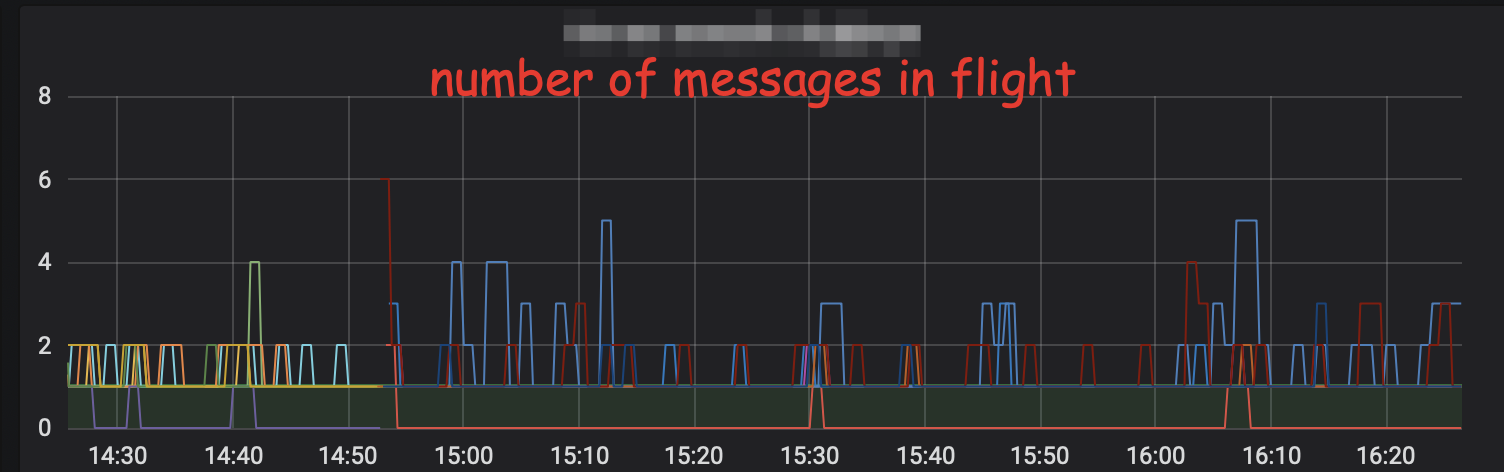
So the proper fix is to limit the possible amount of concurrent connections. Fortunately, it can be done outside of the resource-pool again.
withResourceLimited :: Pool a -> (a -> IO b) -> IO b
withResourceLimited = unsafePerformIO $ do
lookupEnv "DB_CONNECTION_LIMIT" >>= \case
Just (reads -> [(n,"")]) | n > 0 -> do
lock <- newQSem n
pure $ \pool f ->
bracketOnError
(waitQSem lock >> newIORef True)
(\ref -> readIORef ref >>= \x -> when x (signalQSem lock))
(\ref -> withResource pool $ \r -> do
mask_ (signalQSem lock >> writeIORef ref False)
f r)
_ -> pure withResourceThe code here is a bit tricky. The first thought is that we can wrap connection allocation with QSem and get the concurrent connection cap. But it means that we will create a queue of connections that will be actually run. But we don't want to have that instead, and we want to wait for either next free connection or the "ticket" for opening a new one.
We need to allow the next connection to happen ASAP, i.e. when either current connection was allocated or when it failed, and not wait until the end of the transaction.
It's possible to do better, but that would require extending resource-pool package, in the current version of the package started resource allocation it will continue even the next one was freed.
Summary
Now we have a quite stable version that behaves well when connections take too long to run, can handle dead resources in the pool and temporary network failures, and do not overload cluster during that. The best thing is that all of that work was done without altering the package at all. Unfortunately, some of the problems stroke us in the production and lead to the outages, so maybe this post will help others. The question to ask are there any other solutions to the problem. One solution could be to reduce the load during the start. To implement this, one needs to keep a minimal amount of connections opened despite the load. But it's not possible with resource-pool the package without modifications. Other than that, the current solution looks optimal.
P.S. I planned to write this post a few months ago, but approximately at that time we have dealt with another problem that ability to configure a minimal number of the connections is the required property of the pool. So once we have spare cycles we are going to write such a solution (extend resource-pool if possible)
Thanks to Artem Kazak @availablegreen and Andrey Prokopenko @marunarh for useful comments, corrections and suggestions.